数百微服务的依赖管理
如何管理数百个微服务并避免踩坑?
过去两年中,微服务架构是一个非常热门的技术名词。秦苍科技也在微服务方面做了大量的投资和实践,我们有开发、测试、准生产、生产四套环境,每套环境有230+个微服务,总共有近1000个微服务。
秦苍科技为什么要采用微服务的架构?如何管理这么多微服务?本文将对这些问题进行阐述,希望对正在踩坑路上和即将踩坑的朋友们有所帮助。
为什么使用微服务架构?
关于微服务架构优点有很多讨论。但是,个人认为许多优点都可以算作一些“伪优点”。例如:
从单个服务的角度而言,微服务的每个服务都很简单,只关注于一个业务功能,降低了单个服务的复杂性。但是,从整体而言,作为一种分布式系统,微服务引入额外的复杂性和问题,比如说网络延迟、容错性、异步、分布式事务等。
从单个服务的角度而言,每个微服务可以通过不同的编程语言与工具进行开发,针对不同的服务采用更加合适的技术,也可以快速地尝试一些新技术。
但是,从整个公司的角度来说,往往希望能够尽量统一技术栈,避免重复投资某些技术。假设某公司主要用Spring Boot和Spring Cloud来构建微服务,使用Netflix Hystrix作为服务熔断的解决方案。后来,一些微服务开始使用Node.js来实现。很快,该公司就发觉使用Node.js构建的服务无法使用已有的服务熔断解决方案,需要为Node.js技术栈重新开发。
……
我的观点是微服务架构的核心就是解决扩展性的问题。从组织结构的角度来看,微服务架构使得研发部门可以快速扩张,因为每个微服务都不是特别复杂,工作在这个服务上的研发人员不是必须对整个系统都充分了解,很多新人可以快速上手。
从技术的角度来看,微服务架构使得每个微服务可以独立部署、独立扩展,可以根据每个服务的规模来部署满足需求的规模,选择更适合于服务资源需求的硬件。
秦苍科技正处在一个人员规模和业务规模快速扩张的阶段,微服务的扩展性非常贴切地满足了我们现阶段的需求,所以使用微服务架构对秦苍科技来说也变成了一件顺理成章的事情了。
如何进行服务管理?
随着服务数量的增多,我们发觉微服务间的依赖关系越来越复杂,一个服务的改变将会波及多个服务,错误排查也相当困难。当系统有几百个服务时,这种依赖简直就是一个噩梦。
所以,秦苍科技启动了服务治理的项目,使用服务注册和发现技术简化服务的管理,对服务进行了分组、分层,降低系统的复杂性和耦合性。
其实,服务的管理和人员组织结构的管理非常类似。当一个组织中成员增多时,我们会将人员分为若干个小的团队,每个团队由较少的人员组成,负责某个比较独立的业务,并且会有一个团队负责人负责和其他团队的沟通。
当组织中的成员进一步增多时,我们会将若干个团队合并为一个部门,每个部门负责某个独立的职能。
对于微服务的管理,我们采用与组织结构管理类似的方法,把彼此紧密相关的服务构建成逻辑上的一个组。类似于组织结构中的团队负责人,该组有一个API网关,向外暴露了组中所有服务的功能。对于该组中服务的使用方来说,都通过这个API网关进行访问,仿佛这个组就是一个服务一样,无需关心该组是由多少个服务组成。
通过分组的方式,秦苍230+个微服务变为了25个组,从而大大降低了系统逻辑上的复杂性。然后,我们把系统分为了若干层,每一层由若干个组组成。上层只可以调用下层的服务,下层不可以调用上层服务。通过分层的方式,我们降低了系统的耦合性。
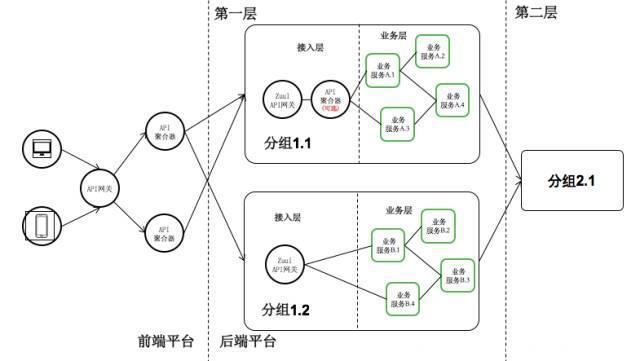
图1 服务分层分组的组织方式输入图片描述
如何让服务管理自动化?
在人员组织结构管理中,为了高效地管理人员的信息,通常会引入一套系统管理这些信息,例如:微软的Active Directory。
当一个新员工入职的时候,我们会在这个系统中添加该成员的基本信息,例如:姓名、电话、email等信息。
在一个员工离职的时候,我们会在这个系统中删除该员工。当一个员工A要和员工B沟通交流的时候,员工A可以根据员工B的姓名在这个系统中查询出员工B的电话、email等信息,然后使用电话或email和员工B进行沟通。
对于微服务的管理,我们也希望有这样一个系统,能够注册和查询微服务的所有信息。微服务架构中把这个系统叫做服务注册中心。
秦苍科技采用了Netflix Eureka作为我们的服务注册中心,所有的微服务都基于Spring Boot和Spring Cloud进行构建。
系统中的每个服务都非常“聪明”,在启动后都会跑到服务注册中心“自报家门”,告诉服务注册中心自己的名字、IP地址、版本、状态、所属组、所属层、所属层的级别、依赖的微服务等信息,服务注册中心会将这些服务保存到它的“花名册”上。
通过服务注册中心的“花名册”,我们可以对系统一览无遗,轻松了解系统的每一层,每一层中所有组,每个组中所有服务的信息。
当服务A依赖于服务B时,它只要知道服务B的名称,就可以从服务注册中心的“花名册”中查询到服务B的所有实例,及其相关的所有信息,例如IP地址、所属组、所属层等信息。
这样,服务A不再需要“死记硬背”服务B的IP地址。当服务A调用服务B的时候,服务A首先从服务注册中心获取到服务B的所有实例,然后服务A采用某种策略从服务B的实例中选择其中一个实例将请求发送给该实例,从而实现了客户端负载均衡。
这个客户端负载均衡的功能就是由图2中的Netflix Ribbon模块来完成的。
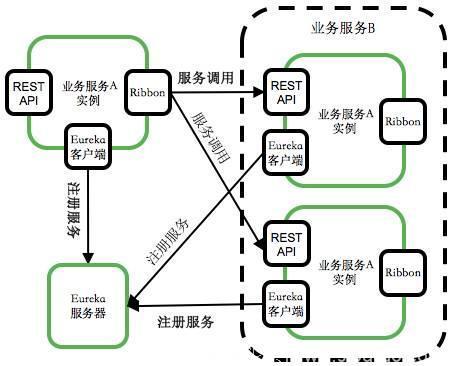
图2 服务注册和发现机制
图2 服务注册和发现机制
如何自动控制服务依赖?
使用前述的方法后,我们可以使用分组分层的方式对服务进行管理。但是,我们仍然需要一定的技术手段来保证开发人员在开发某个微服务的时候一定会遵守下层服务不能调用上层服务的原则,保证开发人员不会引入不该引入的微服务依赖。
秦苍实现自动控制服务依赖的核心是注册服务依赖信息到服务注册中心,扩展Netflix Ribbon限制服务调用。
1.注册服务依赖信息到服务注册中心
每个微服务都会注册该服务所属层、所属层级、依赖的微服务等信息到服务注册中心。这些服务依赖信息作为服务的配置项,保存在配置文件中,统一由运维人员管理。开发人员在开发环境中可以修改这些服务依赖信息,进行开发调试。
但是,在测试、准生产和生产环境中,运维人员会使用自己管理的配置项覆盖掉这些信息,运维只有在经过架构师同意后才会修改这些服务依赖信息。
这就意味着开发无法绕过架构师自行引入新的依赖,否则在测试、准生产和生产环境中服务是调不通的,代码无法正常工作,这样就从技术手段上保证了无法随意地引入微服务依赖。
2.扩展Netflix Ribbon限制服务调用
有了服务依赖信息后,服务调用时我们需要使用这些信息限制不允许的服务调用。只要对Ribbon进行少许扩展就可以满足这样的需求。
本质来讲,Ribbon就是一个服务调用的“路由器”。只要在这个“路由器”上定义一些新的规则,我们就可以控制服务的调用关系。例如:
白名单规则:对于一个微服务,只能调用在该服务白名单列表中的服务,否则调用失败。
层级调用规则:对于一个微服务,只能调用层级比自己低的服务,否则调用失败。
……
目前,秦苍科技对Spring Boot Admin进行了扩展来构建自己的服务治理中心,用户可以按照组的方式浏览服务,查看每个服务的健康状态、配置信息、日志等。
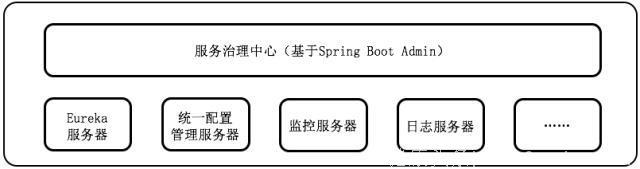
图3 服务治理中心
将来,我们打算通过读取服务注册中心中每个服务注册的元信息,在服务治理中心中自动画出整个系统的架构图。关于自动管控服务依赖方面,我们的工作还在进行中。
希望将来有一天,我们在微服务治理方面的积累足够成熟,可以将这些经验回馈给开源社区。
作者介绍

李荣陆
秦苍科技高级技术总监兼首席架构师。复旦大学计算机博士。曾在Autodesk、SAP、Blackboard等公司担任首席工程师、架构师、高级经理等职位。在国内、国际权威杂志和会议上发表十余篇论文,出版过一本著作。十几年来在云计算、计算机辅助设计、自然语言处理、搜索引擎、数据挖掘、人工智能、机器学习、微服务架构等领域均有涉猎。