精神疾病新划分:五个亚组
各种类型精神疾病的区分仍是精神病学家努力的方向,到目前为止,医生根据症状已经将精神病患者分为两大类——双相情感障碍或精神分裂症,重点关注他们的精神病史的共同要素、症状表现的范围和疾病进展的整体模式。
尽管详细的观察表明,精神疾病和潜在的遗传风险因素比传统的诊断二分法所显示的更具有异质性,但这种分类仍然是临床实践和精神病学研究的基本。
确定精神疾病亚组可以提高临床和研究的准确性。目前研究集中在症状亚组上,但有必要考虑更广泛的临床谱,弄清疾病的发展轨迹,并研究遗传相关性。
由LMU的Nikolaos Koutsouleris领导的精神病学家使用了一种基于计算机的方法,将诊断为双相情感障碍或精神分裂症的精神病患者分配到五个不同的亚组中。这种方法可能有助于更好地治疗精神疾病。
研究概况
这项正在进行的多地点、自然主义、纵向(6个月的间隔)队列研究始于2012年1月,覆盖18个地点。收集来自1223名个体的参考样本(发现样本765人,验证样本458人)的数据,这些样本具有DSM-IV诊断的精神分裂症、双相情感障碍(I/II)、分裂情感性障碍、精神分裂症样障碍和短暂性精神障碍。发现数据于2016年9月提取,并于2016年11月至2018年1月进行分析,2018年10月提取前瞻性验证数据,2019年1月至5月进行分析。
研究应用数据驱动的方法检测精神病亚组,并对精神分裂症、双相情感障碍、重度抑郁症和教育成就的疾病病程(1.5年以上)和多基因评分进行检查。
采用非负矩阵分解聚类方法,对188个变量组成的临床指标组进行了分析,包括测量人口统计学特征、临床病史、症状、功能和认知。将亚型特异性疾病过程与混合模型和多基因评分进行比较,并进行协方差分析。
结果
在发现样本的765人中,女性341人(44.6%),平均年龄42.7岁(12.9岁)。5个亚组分别标记为情感性精神病(n=252)、自杀性精神病(n=44)、抑郁性精神病(n=131)、高功能性精神病(n=252)和重度精神病(n=86)。
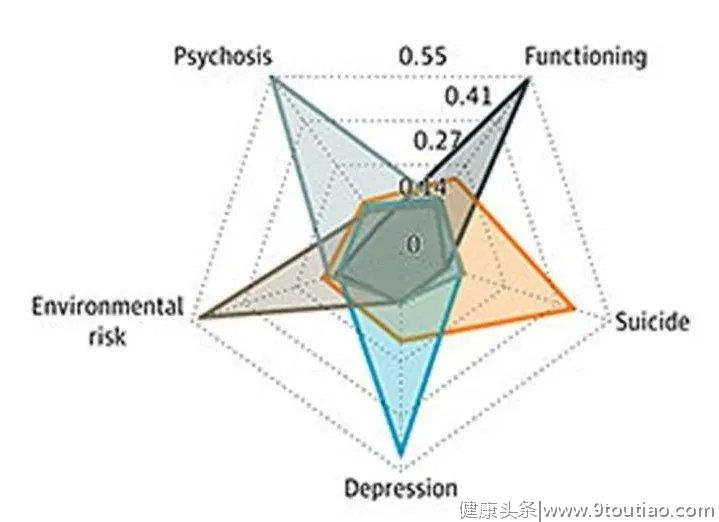
发现具有明显二次交互作用的疾病过程包括精神病症状(R2=0.41; 95%CI,0.38-0.44),抑郁症症状(R2=0.28; 95%CI,0.25-0.32),整体功能(R2=0.16; 95百分比CI,0.14-0.20)和生活质量(R2=0.20;95%CI,0.17-0.23)。
抑郁和严重精神病亚组表现出最低的功能和二次病程(部分恢复,重症再发)。
受教育程度多基因评分存在差异(平均(SD)部分η2 = 0.014[0.003]),但诊断性多基因风险未发现差异。
结果在验证队列中被大量复制。
结论和相关性
精神病亚组具有独特的临床特征、病程和非诊断性遗传标志物的特异性。新的数据驱动的临床方法对未来的精神病分类至关重要。
研究评论
研究人员对1223名患者进行了为期18个月的纵向队列研究。所获得的结果使研究小组将患者分成5个定义明确的亚组,从而提供了一个更精细的精神病病理学图像,这对治疗干预具有重要意义。
本研究旨在确定是否可以根据统计相关变量的聚类,将涵盖广泛精神疾病的高维度临床数据集分解为定义的亚组。所采用的数据驱动分析策略是基于机器学习的,它可以发现在大量多因素数据中揭示“隐藏结构”的模式。这些模式可能反过来提示与诊断相关的因果关系差异。
该研究发表在JAMA Psychiatry上,研究的第一作者Dominic Dwyer 说:“我们的研究表明,基于计算机的分析确实可以帮助我们重新评估那些精神病患者是如何被诊断出来的”。
分析最终在实验人群中识别出五个定义明确的亚组。领导这项研究的Nikolaos Koutsouleris说:“除了症状和功能过程上的差异外,被分配到不同亚组的病人也可以根据定义的临床指征来区分。”其中一个亚组的成员与其他所有人的区别还在于他们的低教育程度分数,这是已知的精神疾病的潜在危险因素。
研究人员使用了一种称为非负矩阵分解的数学方法来检测统计数据中的模式。通过使用这个过程,他们能够将包含188个变量的初始数据集简化为由核心因素定义的五个亚组。这些因素编码了变量之间迄今未被识别的关系,并揭示了它们之间的功能联系。
Dwyer解释说:“通过评估这些因素在个别病例中的相对重要性,就有可能根据患者的总体得分将他们分成不同的组。”通过这种方式,研究的作者定义了以下五种精神疾病亚组:情感性精神疾病、自杀性精神疾病、抑郁性精神疾病、高功能性精神疾病和重度精神疾病。
Koutsouleris说:“根据临床数据,每个亚组都可以与其他所有亚组明确区分开来。”例如,被分配到第5组的患者的特征在于核心因素:精神分裂症的诊断、明显较低的受教育程度和言语智力低下。该类患者多为男性,有明显的精神病症状,无抑郁、躁狂症状。另一方面,在第二组中,明显存在自杀倾向。这一实验群体的分类结果为建立统计模型提供了基础数据,并在458名独立受试者中得到证实。
分析表明,无偏倚的、数据驱动的聚类可用来将个体划分为具有不同临床特征、疾病轨迹和遗传基础的群体。在未来,可以通过使用在线工具将这种计算机辅助分类集成到临床常规程序中。Koutsouleris和他的团队已经开发了这种在线工具的原型,可以用来将新个体分组,并预测测试的结果。